| author: | liaojh1998 |
| score: | 9 / 10 |
TODO: Summarize the paper:
-
What is the core idea?
Empirical studies show that vision Transformers are data-hungry, but the data requirements can be fulfilled with self-supervising pre-training methods. BERT (Devlin et al., 2019), on the other hand, has achieved great success in NLP by leveraging the Masked Language Modeling (MLM) self-supervised pre-training objective. The authors propose to create a BERT-style vision Transformer, BEiT, by pre-training it on the self-supervising objective, Masked Image Modeling (MIM), which is the same as MLM but masking image patches and predicting visual tokens.
-
How is it realized (technically)?
There are 2 types of Image Representations, and these are described below:
- Image Patch: Split the 2D image \(\textbf{x} \in \mathbb{R}^{H \times W \times C}\) into \(N = HW/P^2\) patches. Original 2D image has dimensions \((H, W)\). A patch has dimensions \((P, P)\). \(C\) is the number of channels. In this paper, \(H = W = 224\), and \(P = 16\). So, the image is split into a \(14 \times 14\) grid of \(16 \times 16\) image patches. (Refer to the left column of procedures in the figure below.)
- Visual Token (Ramesh et al., 2021): Trains a tokenizer to tokenize the image into discrete tokens according to a visual codebook (i.e. vocabulary). This is done by training a tokenizer and a decoder module, both of which are discrete variational autoencoders (dVAE). (Refer to the top row of procedures in the figure below)
- Tokenizer: First, tokenize the image into a \(14 \times 14\) grid, then map each patch on the grid to some token in vocabulary \(\mathcal{V}\). The vocabulary size is set to \(\|\mathcal{V}\| = 8192\), and the dVAE map the image patch into a distribution over the 8192 tokens (indices) to take the
argmax. - Decoder: Reconstructs the image according to the \(14 \times 14\) visual tokens outputted by the tokenizer. Since visual tokens are discrete (after taking
argmax), the model training is non-differentiable. Gumbel-softmax relaxation (Jang et al., 2017; Maddison et al., 2017) is employed to train the tokenizer-decoder end-to-end.
- Tokenizer: First, tokenize the image into a \(14 \times 14\) grid, then map each patch on the grid to some token in vocabulary \(\mathcal{V}\). The vocabulary size is set to \(\|\mathcal{V}\| = 8192\), and the dVAE map the image patch into a distribution over the 8192 tokens (indices) to take the
- Note that the number of image patches and number of visual tokens are the same for the pre-training objective.

The ViT backbone of BEiT is the standard Transformer (Vaswani et al., 2017). Input to the transformer are linear projections of the flattened image patches (at the bottom of the figure). 1D learnable position embeddings are also added to the projections.
BEiT is pre-trained using the Masked Image Modeling (MIM) objective, which is a spin-off of the Masked Language Modeling objective (Devlin et al., 2019). Some of the image patches are masked for the model to predict the corresponding visual tokens. Instead of masking random patches, a block of the image is masked (see bottom left of the figure). This is similar to the work done in other blockwise masking BERT-like models (e.g. SpanBERT of Joshi et al., 2020). Then, the pre-training objective is just to maximize the log-likelihood of the correct visual tokens (from the tokenizer), \(z_i\), given the corrupted image with masked patches, \(x^\mathcal{M}\):
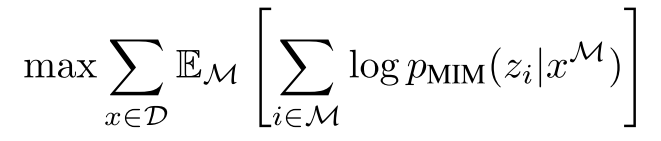
This pre-trained can be viewed as variational autoencoder (Kingma and Welling, 2014) training. Refer to section 2.4 in the paper for more information.
The pre-trained is done on the training set of ImageNet-1K with augmentations. The labels are not used for the self-supervised training. Training for 500k steps took about 5 days using 16 Nvidia Tesla V100 32GB GPU cards.
-
What interesting variants are explored?
After pre-training BEiT, the authors appended a task layer upon the Transformer, and fine-tuned the parameters on downstream tasks:
- Image Classification: Linearly project all BEiT representation outputs with a matrix, aggregate with an average pool, then apply a softmax for classification. Both parameters of BEiT and the softmax classifier are updated during fine-tuning.
- Semantic Segmentation: Use BEiT as a backbone encoder, and incorporate several deconvolution layers as decoder to produce segmentation (Zheng et al., 2020). This is also fine-tuned end-to-end like image classification model.
After the self-supervised pre-training, the authors also tried fine-tuning BEiT on a datarich intermediate dataset (i.e. ImageNet-1K) with supervision before fine-tuning the model on target downstream tasks. This procedure is denoted as “Intermediate Fine-Tuning” in the results.
-
How well does the paper perform?
- Image Classification:
- Dataset: ILSVRC-2012 ImageNet dataset (1k classes and 1.3M images) (Russakovsky et al., 2015) and CIFAR-100 (100 classes and 60k images) (Krizhevsky and Hinton, 2009).
- Metric: Top-1 Accuracy (the conventional accuracy, which is what the model classify with the highest probability).
- Used most of hyperparameters of DeiT (Touvron et al., 2020) in the fine-tuning experiments for a fair comparison.
- Results:
- Self-supervised Pre-trained BEiT performed comparably to other models on CIFAR-100, and outperforms all other models (trained from scratch, supervised pre-trained, and self-supervised pre-trained) on ImageNet.
- Additional intermediate fine-tuning on ImageNet (supervised fine-tuning with labels) allowed BEiT to outperform all other models on CIFAR-100.

- Additional Variants Results:
- Fine-tuning on higher resolution images (\(384 \times 384\) instead of \(224 \times 224\)) improved BEiT results by 1+ points on ImageNet.
- Scaling BEiT up to a larger size improved performance in general.
- BEiT with self-supervised pre-trained converged much faster than training DeiT from scratch.

- Semantic Segmentation:
- Dataset: ADE20K benchmark (25k images and 150 semantic categories) (Zhou et al., 2019).
- Metric: Mean Intersection over Union (mIoU) averaged over all semantic categories.
- Used most of the hyperparameters decribed in SETR-PU (Zheng et al., 2020).
- Results:
- Self-supervised pre-training (without labels) did better than supervised pre-training (with labels) on ImageNet.
- Additional intermediate fine-tuning (with labels) on ImageNet allowed BEiT to perform better on ADE20K.

-
Ablation Results (\(-\) is without, \(+\) is with)

-
Self-attention mechanism in BEiT can separate objects, even when pre-training is self-supervised and does not rely on any manual annotation.

- Image Classification:
TL;DR
- BEiT is a Vision Transformer that is pre-trained in a similar fashion to BERT.
- BEiT is trained on the Masked Image Modeling objective.
- BEiT masks blocks of image patches and predict the visual token of each image patch.