| 2024 | |
|---|---|
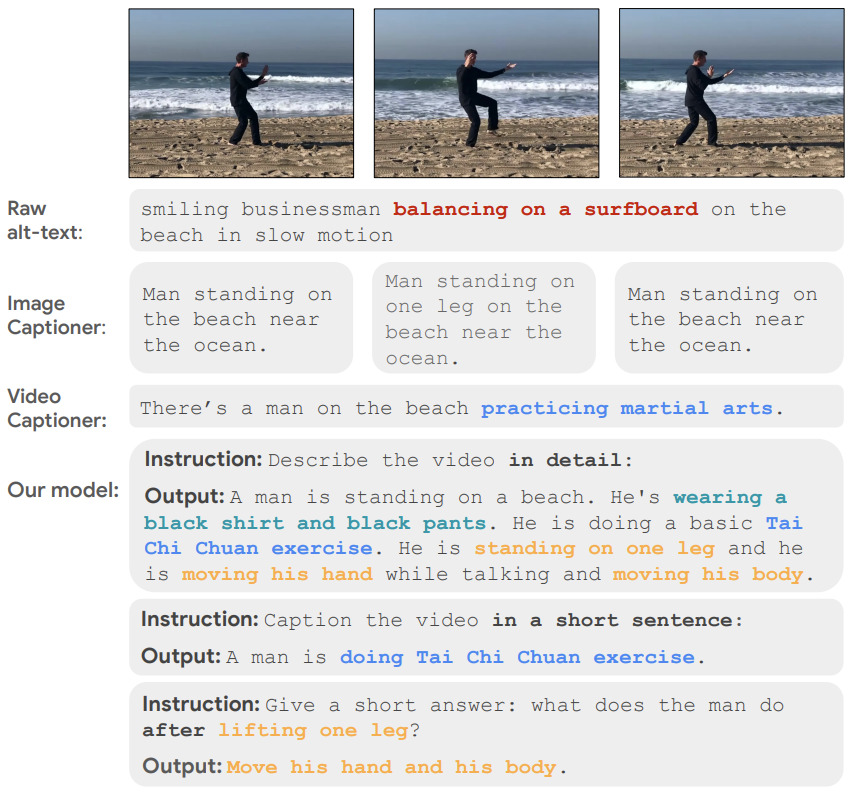 | Distilling Vision-Language Models on Millions of Videos Yue Zhao, Long Zhao, Xingyi Zhou, Jialin Wu, Chun-Te Chu, Hui Miao, Florian Schroff, Hartwig Adam, Ting Liu, Boqing Gong, Philipp Krähenbühl, Liangzhe Yuan CVPR 2024 arxiv |
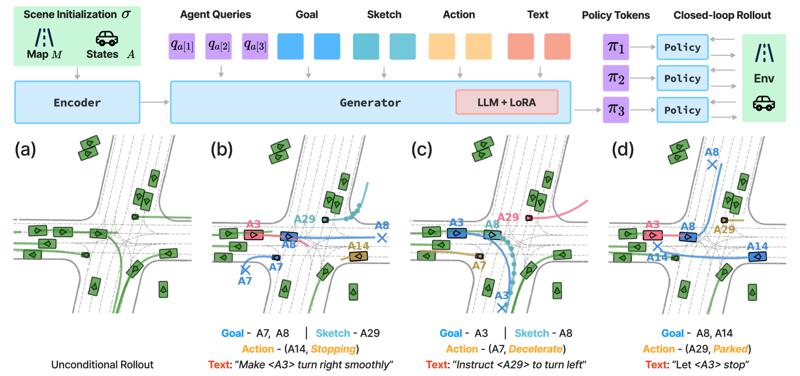 | Promptable Closed-loop Traffic Simulation Shuhan Tan, Boris Ivanovic, Yuxiao Chen, Boyi Li, Xinshuo Weng, Yulong Cao, Philipp Krähenbühl, Marco Pavone CoRL 2024 arxiv |